 登录 / 注册
登录 / 注册
能力跃升、应用下沉,百度大脑打造人工智能时代的驱动引擎
发布时间:2021-12-29
标签:
作为百度AI多年技术积累和业务实践的集大成,百度大脑已发展成为全球领先的人工智能平台。12月28日,百度Create AI开发者大会“百度大脑论坛”举办。论坛围绕打造人工智能时代的驱动引擎展开探讨,带来了百度大脑语言与技术、语音和视觉等多项技术产品的发布,以及飞桨在开源算法模型、产业级模型库和企业级AI应用开发等方面的全新升级。
百度大脑语言与知识技术全布局,三大技术产品重磅发布
百度技术委员会主席吴华在论坛上表示,经过11年的发展,百度已形成了完整的语言与知识技术布局,包括知识图谱、语言理解与生成技术和应用系统等。随后,吴华带来了三大技术产品的发布:全球首个知识增强超大模型鹏城-百度·文心,全球最大中文跨模态生成模型 ERNIE ViLG,以及首个百亿参数中英对话预训练生成模型 PLATO-XL,实现了知识增强大模型、跨模态文图生成、人机对话等领域的世界领先。

特别是全球首个千亿知识增强的大模型鹏城—百度·文心,得益于鹏城实验室的算力系统“鹏城云脑Ⅱ”和飞桨深度学习平台的强强联手,解决了超大模型训练的多个公认技术难题,使训练效率大幅提升,模型效果更优。鹏城-百度·文心已经在机器阅读理解、文本分类、语义相似度计算等60多项任务取得最好效果,并在30余项小样本和零样本任务上刷新基准。
基于百度的语言与知识技术,百度也面向各行业开放了语言与知识开放平台。不仅包含开源数据集“千言”和知识生产平台“解语”,还研发了面向应用的能力引擎平台和知识中台,以及智能文档分析平台、智能对话定制平台、智能创作平台、翻译开放平台和内容审核平台等场景定制平台。
百度语音技术重要进展,SMLTA2全新发布
语音和语言天生更接近,因此,把语音识别模型和语义模型进行一体化后的准确率和交互成功率会大幅提升。百度语音首席架构师贾磊介绍了百度多模态语音交互的最新进展。百度提出的基于历史信息抽象的流式截断Confomer建模技术——SMLTA2,解决了传统的自相关技术在进行长句识别时的计算爆炸问题和存储爆炸问题,也很好地解决了注意力模型的焦点丢失问题。

SMLTA2通过Decoder到Encoder各层的注意力特征选择机制来引入反馈,使得最外层识别结果信息可以直接作用于编码器内部的每一层的编码过程,通过历史信息抽象充分提取有效特征信息,显著改善了Transformer模型从NLP领域应用到语音识别领域面临的各种问题。SMLTA2的这种全新的端到端建模方法,是对传统Encoder-Decoder结构的端到端建模的结构性创新。
最后,贾磊还介绍了SMLTA的实际商业落地情况。浦发银行在全国多个营业厅上线了语音交互系统,其中位于上海外滩的银行网点语音交互识别率测试达到93.51%,语音交互已经由完全不可用变成基本可用。
智能视频创作,计算机视觉的最新实践
百度视觉技术部总监丁二锐重点介绍了计算机视觉在智能视频创作中的最新进展。现阶段,视频内容生产正在由UGC(用户生成内容)向AIGC(AI 生产内容)转变。
智能视频创作是一个多技术交叉融合的领域,对于一个创作者而言,同时掌握视觉生成、多模态、3D图形学并不现实,但百度智能视频制作技术兼顾内容创意和视频功能创作,不仅实现了对人脸、人体的精细处理和环境的再塑造,在创作方法上,改善存量视频并获取新增视频,保障了视频的充足展现和分发。
丁二锐表示,智能视频创作领域目前呈现蓬勃发展的态势,技术的发展带来了生产工具的变革,一旦与其他生产要素结合,将带来无尽的想象力。

飞桨产业级平台再升级,让AI应用门槛更低
除了技术上的融合创新,在工具与平台方面,飞桨从开源算法模型、产业级模型库和企业级AI应用开发等方面实现升级,持续降低AI应用的门槛。
百度杰出架构师毕然分享道,目前百度飞桨官方支持的产业级开源算法模型超过400个,覆盖计算机视觉、自然语言处理、语音和推荐等众多深度学习应用领域。这样全面覆盖,使开发者可以很快地找到所需要的模型。并且这些产业级模型库实现了训练部署的全流程支持,开发套件支持灵活配置化调优。
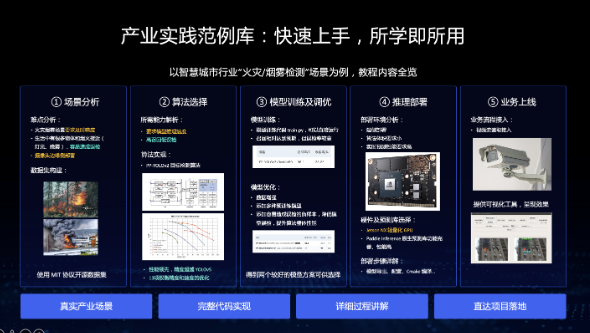
毕然还详细介绍了飞桨最新推出的产业实践范例库。针对产业实际场景的AI应用,范例库提供完整的代码实现,覆盖任务解析、算法选择、模型训练及优化、推理部署及结果可视化等产业落地全流程,让开发者快速上手,所学即所用。
百度智能云AI产品研发部总监忻舟介绍了飞桨企业版AI开发双平台EasyDL和BML在帮助开发者快速提升AI开发效率和资源使用效能的上的有效助力。
目前,飞桨企业版已经成为应用和落地最广泛的AI开发平台。基于双平台的开发模式,同时满足AI应用开发者和AI算法开发者的需求。基于飞桨推理部署工具链,飞桨企业版已经为开发者测试并验证了9345种模型芯片的组合,能够覆盖95%的适配需求,能够节省开发者97%的自行适配开发时间。PaddleSlim结合全自动的模型组合压缩算法,能够使精度损失控制在1%以内时,推理的性能提升3到5倍;智能边缘控制台的推出,则大幅提升模块和系统集成的效率,集成的周期可以从天缩短到五分钟。

百度知识图谱部、大数据部高级总监朱勇详细介绍了在工业领域,百度打造的工业数据智能引擎如何降低AI的应用门槛。
朱勇表示,随着产业数字化进程不断深入,大数据的应用趋势也逐渐从业务数据化发展到数据智能化,工业数据智能前景广阔,机遇和挑战并存。百度基于领先的人工智能大数据技术,面向工业场景,打造了一套完整的工业数据智能引擎。它向下对接大数据平台,实现数据治理,向上支撑各种类型的业务场景需求,赋能电力能源、钢铁、化工、汽车制造等不同行业。百度工业数据智能引擎的核心是一系列可复用的工业模型以及支持定制化模型搭建的核心组件,包括数据分析、数据处理、AI算法和工业机理。
以钢铁行业为例,为了保证镀锌板具有良好的力学性能,需要根据钢板的原料信息对镀锌工艺参数进行必要的调整。基于百度工业数据智能引擎可以进行力学性能预测,达到90%以上的准确率, 通过工艺参数寻优,产品合格率达到99%。通过应用这套方案,企业客户不仅能够提升产品质量;相比传统基于人工经验的方式,还能大幅降低调试时间,从而提升生产效率。
最后,朱勇强调,在大数据和AI加速向工业渗透的背景下,工业数据智能前景可期。百度期待携手更多开发者,共同助力工业智能化升级。

接下来,百度大脑将持续进化,不断推动AI技术提升,通过融合创新,让AI能力越来越强,与此同时,降低AI应用的门槛,让技术的落地更加简单,帮助越来越多行业和企业借助AI提升效率,创造价值。
文章来源:财讯网
需求提交
最新资讯
1
第三期“满天星计划”——中关村轨道交通产业项目投资路演活动在丰台创新中心成功举办!
2
坚决扛起做支撑当引领的职责使命 当好全市高质量发展的主引擎和增长极
3
商务部等17部门关于搞活汽车流通扩大汽车消费若干措施的通知
4
有特色有亮点有实效 政策性开发性金融工具持续落地
5
精准对接地方产业发展 2亿元政策性资金带动4.8平方公里“双碳产业园”
6
用好税制杠杆,全国人大代表呼吁:扩大15%所得税优惠政策实施范围
7
选址内参 | 想去天津投资选址,应该选择哪个产业园区?
8
汽车整车企业如何选址?
9
今日,表决、选举!
10
十项行动32条政策措施!《上海市提信心扩需求稳增长促发展行动方案》发布




